1. 引言
全球气候变暖的问题正在严重威胁着整个人类自身的健康生存和社会发展,受到世界范围内各个国家的普遍重视。对于温室气体的排放问题,国家已经高度重视并做出了相应的举措,根据2017年发布的《能源生产和消费革命战略(2016~2030)》,明确提出2030年时能源碳排放强度应较2005年降低60%~65%,并积极争取在2030年尽早达到二氧化碳排放峰值。
安徽省是我国煤炭资源富足的大省,也在积极融入长三角一体化发展,具有重要的经济地理位置。但是安徽经济发展以粗放型经济增长为主,使得能源消费也随之增长,这给安徽省的碳减排工作带来了巨大的压力。根据《安徽省碳达峰实施方案》所述,安徽省旨在实现2030年前的碳达峰目标。具体而言,计划在2030年时,非化石能源在总能源消费中的占比达到22%以上,单位地区生产总值的二氧化碳排放较2005年减少65%以上。因此,分析安徽省二氧化碳排放影响因素,构建二氧化碳排放预测模型就显得尤为重要。本文通过运用灰色系统理论,对安徽省2000~2022年相关影响因素进行关联度分析,选取高关联度因素作为BP神经网络的输入变量,使用近19年的数据进行训练和验证,并对2023至2027年安徽省二氧化碳排放量进行了预测。
2. 文献综述
二氧化碳排放预测模型是用来预测未来某个时间段内的二氧化碳排放量的模型。这种模型可以基于历史数据和其他相关因素,对未来的二氧化碳排放进行估计。二氧化碳排放受多种因素的影响,包括经济活动水平、能源结构、人口增长、工业化程度、技术创新等。在构建二氧化碳排放预测模型时,需要考虑这些因素,并选择合适的建模方法。
关于二氧化碳排放量预测,学术界有着丰富的研究。白义鑫 [1] 等人首先利用Tapio脱钩模型对贵阳市农业生产碳排放和农业GDP进行了脱钩关系的分析,之后运用GM (1, 1)进行未来10年贵阳市农业碳排放的预测。张国兴 [2] 等人对长江流域交通运输首先利用了LMDI法对各种影响因素进行分解,再针对于不同情景下通过STIRPAT模型预测碳排放趋势。杨楠 [3] 等人对唐山市钢铁行业利用LEAP软件构建了钢铁生产碳排放预测模型,并研究得出在2018年唐山市钢铁生产碳排放已经达峰。李坦 [4] 等人针对于安徽省能源消费碳排放首先运用LMDI法进行驱动因素的分解,再对其进行碳排放量差异性分析,最终进行蒙特卡洛模进行动态模拟。严慈 [5] 等人对陕西省土地利用变化各影响因素与其碳排放进行灰色关联分析,最后运用GM (1, 1)模型对未来10年的陕西省土地碳排放量进行了预测。胡振 [6] 等人对西安市家庭消费碳排放构建了BP神经网络模型,通过与多元线性回归模型进行比较,发现其预测方法具有良好的效果。
通过上述综述,二氧化碳排放预测模型有很多种,但是由于二氧化碳排放影响因素多种多样,不同的预测模型预测出来的结果都是不同的,为此为了探究预测结果更加精准的模型,本文针对于安徽省二氧化碳排放进行了相关预测研究。
3. 基于灰色-BP神经网络预测模型构建
3.1. 灰色关联分析简介与计算步骤
灰色系统理论是1981年由邓聚龙教授提出的一种主要应对数据稀缺和贫信息不确定性问题的新兴方法。各要素之间的关系由于数据的不稳定和信息的不明确难以直接辨识时,灰色系统理论成为一种探究这些关系的有力工具。计算得出的灰色关联度是用来衡量两者之间同步变化程度。数值越接近于1,二者的关联程度越高;反之,数值越接近于0,二者则存在越弱关联程度。我国的数据统计难以展现典型的规律分布,存在一定的局限性,因此常规的数理统计方法难以获得令人满意的结果。而采用灰色关联分析法能够有效解决这些问题,为探讨数据关系提供了可行途径 [7] 。
假设在评价系统中存在n个评价对象,而且这些评价对象每个都存在m个评价因子 [8] 。通过将这些评价对象和评价因子进行矩阵构建,形成了一个属性矩阵:
(1)
在所述公式(1)中,
代表第j个评价对象在第i个评价因素下的指标属性。在进行灰色关联分析时需要选择参考序列和比较序列,这些都需要根据实际情况进行确定。设:参考序列为
,且
比较序列为
,
和
。灰色关联度的计算步骤如下:
1) 归一化处理
由于原始数据来源范围广、量纲不一致,可能存在较大的差异,因此无法直接对其进行比较。对数据进行预处理,能够有效的减少差异,确保数据的可比性,其中预处理方法包括初值化和均值化等方法。在本研究中采用了初值化方法。
2) 求差序列
绝对差序列是指将两个数列差进行绝对值操作。
3) 求两极最大差和最小差
4) 求关联系数
在上述公式中,
代表分辨系数,其取值范围一般在为0到1之间。其主要是用于提高关联系数显著性,减小由于最大值过大而引起的误差。通常选择分辨系数为0.5。
5) 计算灰色关联度
由于相关系数用于衡量两个序列在不同时间点上的关联度,因此涉及的相关系数较为繁多。为更直观地比较这些相关系数,可将各相关系数进行平均处理,以平均值表示其的关联程度。
关联度可以帮助我们了解二氧化碳排放与其影响因素的相互影响程度。
3.2. BP神经网络
BP神经网络是一种多层前馈神经网络,其结构包括输入层、隐含层和输出层。其主要特征在于通过信号的前向传递和误差的反向传播进行信息处理。在前向传递阶段,输入信号从输入层经过隐含层逐层传递,直至到达输出层。每一层中的神经元状态仅影响下一层神经元的状态。若输出层未能产生期望输出,则进入反向传播阶段,通过调整网络权值和阈值以适应预测误差 [9] 。
在进行BP神经网络预测之前需要进行神经网络的训练,通过训练使得该神经网络能够具备联想记忆和预测能力。所以需要设置训练集和验证集,通过输入训练集,对模型进行训练,在使用验证集进行验证,用来判断该BP神经网络的预测准确性。
3.3. 构建基于灰色-BP神经网络预测模型
本文构建的模型是先使用灰色关联分析,计算出各影响因素的关联度,筛选出高关联的因素。再选取这些高关联度的因素作为BP神经网络的输入层进行训练与验证,最终利用构建好的预测模型进行相关的预测。模型构建图如图1。
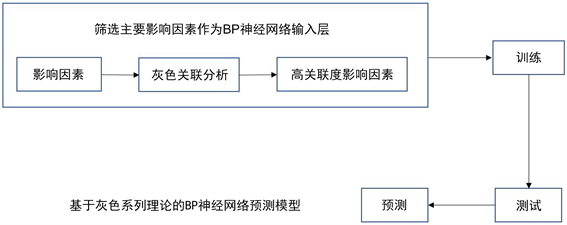
Figure 1. Flow chart of prediction model based on gray correlation analysis and BP neural network
图1. 基于灰色关联分析与BP神经网络预测模型流程图
4. 基于灰色-BP神经网络的安徽省二氧化碳排放预测模型
4.1. 安徽省二氧化碳排放影响因素灰色关联度计算
借鉴相关二氧化碳排放影响因素研究结果,选取安徽省2000~2022年共23年相关指标数据,构建灰色关联分析模型(表1),数据来源于《安徽省统计年鉴》。

Table 1. Indicator system of factors affecting carbon dioxide emissions in Anhui Province
表1. 安徽省二氧化碳排放影响因素指标体系
关于二氧化碳排放量的计算,根据OECD于2002年和IPCC于2006年发布的国家温室气体清单指南中的二氧化碳排放计算指南 [10] ,公式为
其中
为第j种能源的二氧化碳排放量,
为第j种能源的二氧化碳排放系数,
为第j种能源的消耗量;根据IPCC发布的国家温室气体清单指南,并借鉴蔡俊 [11] 等方法,计算出常见八种化石能源的二氧化碳排放系数如表2。
Table 2. Carbon dioxide emission coefficients of common energy sources
表2. 常见能源二氧化碳排放系数
本文以二氧化碳排放量为参考序列,将其他影响因素作为比较序列。随后,对各指标进行归一化处理,并在灰色关联度计算过程中选取分辨系数ξ为0.5。通过这一步骤,得到了安徽省二氧化碳排放量与各个影响因素之间的灰色关联值,具体结果见表3。
Table 3. Gray correlation between carbon dioxide emissions and influencing factors in Anhui Province
表3. 安徽省二氧化碳排放与其影响因素灰色关联度
当灰色关联度大于0.85时,两指标之间存在高度关联。因此,根据所得灰色关联度大小,选取高度关联的指标进行BP神经网络构建。
4.2. BP神经网络模型的构建
根据安徽省二氧化碳排放与其影响因素灰色关联度计算结果,选取人口、人均GDP、城镇化率、工业化水平率、第三产业产业贡献率、能源消费总量、电力消费总量和农林牧渔业增加值建立BP神经网络预测模型。把人口、人均GDP、城镇化率、工业化水平率、第三产业产业贡献率、能源消费总量、电力消费总量和农林牧渔业增加值作为输入变量,把安徽省二氧化碳排放量作为输出变量,输入层为8,隐含层节点数量为6,输出层为1,将训练次数设置为1000次,学习速率为0.1,训练目标最小误差为0.00001 [12] 。利用Matlab软件构建模型,BP神经网络模型结构图如图2。
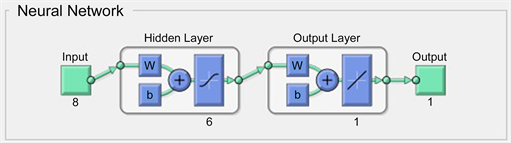
Figure 2. BP neural network model structure diagram
图2. BP神经网络模型结构图
4.3. BP神经网络模型的训练和验证
该预测模型选取2000~2018年数据为训练集,2019~2022年数据为验证集,通过Matlab软件进行学习、验证。由于各权值和阀值的随机性,导致每次训练的结果都不同,选择平均绝对百分比误差为0.0113的训练结果。该模型预测2019~2022年安徽省二氧化碳排放预测曲线图如图3,该模型预测2019~2022年的安徽省二氧化碳排放结果如表4。
从结果中可以明显得到,该模型预测值与实际值误差较小,具有良好的预测效果。
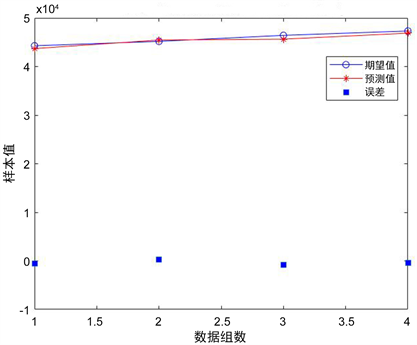
Figure 3. Anhui Province carbon dioxide emission prediction curve based on gray-BP neural network combination
图3. 基于灰色-BP神经网络组合的安徽省二氧化碳排放预测曲线图
Table 4. Carbon dioxide emission prediction results in Anhui Province based on gray-BP neural network combination
表4. 基于灰色-BP神经网络组合的安徽省二氧化碳排放预测结果
4.4. 不同预测方法预测结束对比
利用数据,分别出计算GM (1, 1)、BP神经网络和基于灰色-BP神经网络组合模型的预测结果,预测结果绘制如图4所示。通过对预测的输出结果与真实二氧化碳排放量计算得三种预测模型的平均相对误差如表5所示。
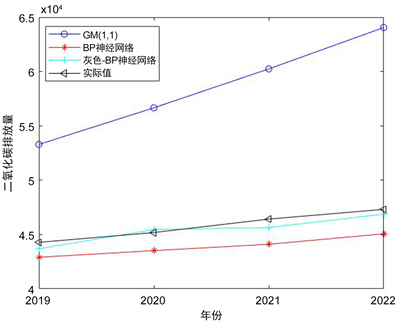
Figure 4. Prediction results diagram of three prediction models
图4. 三种预测模型的预测结果图
Table 5. Prediction values and average relative errors of three prediction models
表5. 三种预测模型的预测值和平均相对误差
由预测结果和实际值的对比更加可以得出,基于灰色系统理论与BP神经网络组合模型误差最小,属于高精度预测(平均绝对百分比误差小于10%),具有良好的预测效果。
4.5. 基于灰色-BP神经网络模型预测
由于2023至2027年的相关数据尚且没有,借助GM (1, 1)依据2000至2022年的相关数据进行未来五年数据的计算Y1~Y8的平均绝对百分比误差,其中最大值是Y2 (人均GDP)为18.69%,属于良好预测,最小值为Y1 (人口) 0.89%,属于高精度预测,八种数据的平均值为7.91%,预测效果良好,数据可以进行后续的灰色-BP神经网络预测。因此对安徽省2023~2027年的二氧化碳排放量进行预测,预测结果分别为47234.16万吨、47286.26万吨、47324.98万吨、47352.94万吨、47372.74万吨。预测结果见图5。
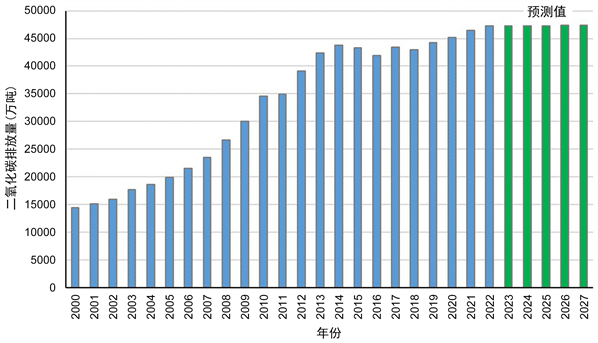
Figure 5. Carbon dioxide emissions in Anhui Province from 2000 to 2027
图5. 安徽省2000至2027年二氧化碳排放量状况
虽然安徽省2023~2027年的二氧化碳排放量呈上升趋势,但是总体上升较少,趋于稳定,由此可见安徽省目前采取的措施对二氧化碳排放起到了一定的作用。
5. 结论
本文建立了安徽省二氧化碳排放量的灰色-BP神经网络组合预测模型,主要得到了以下结论。
1) 由于二氧化碳排放的影响因素较为复杂,很难利用线性回归进行预测。因此本文使用灰色关联分析筛选出影响二氧化碳排放的主要因素。后使用非映射能力较强的BP神经网络模型很巧妙地解决了线性无法解决的问题 [13] 。
2) 利用灰色-BP神经网络的组合预测模型,不仅提高了BP神经网络的训练速度,减少了时间成本,与传统的BP神经网络相比,还提高了预测的准确性与实用性。
3) 本文利用该预测模型成功预测出安徽省2023~2027年的二氧化碳排放量,与往年相比,二氧化碳排放量增加较少,趋于稳定,可见安徽省目前采取的碳减排措施具有较好的效果。
4) 本文仅仅利用了该预测模型预测了安徽省未来五年的二氧化碳排放量,并没有预测出碳达峰和碳中和的时间,故在今后的研究中会继续深入研究,采用情景模拟的方法进行安徽省碳达峰碳中和的预测。
基于以上研究结论,安徽省要在2030年前实现碳达峰目标,必须坚持节能减排,采取一系列有效的措施来减少碳排放。首先,要发挥政府的主导作用,推动产业结构的转型升级,减少高碳排放产业的比重,发展低碳产业。通过技术创新和工艺改进,提高能源利用效率,减少能源消耗,从而减少碳排放。其次,企业要采用先进的节能减排技术,降低生产过程中的耗能和排放。同时政府要加强对高污染、高排放企业的监管和治理,推动企业实施节能减排措施,降低碳排放。通过坚持节能减排,中国有望在2030年实现碳达峰的目标,为全球应对气候变化做出积极贡献。